
スクレイピングとは?
インターネット上にある情報を自動でとってきて処理をするなんて時に使うのが「スクレイピング」という技術です。
例えば定期的に更新される天気予報のデータを指定してとってきて、雨の予報が出たらメールで知らせるとか、株価が指定した値まで下がったら連絡するといった時にはwebページにある情報が必要ですね。その情報をとってくるときに使うのがスクレイピングです。
天気や株価なんてアプリがあるじゃない?と思われる方もいると思いますが、全くその通りです。しかし、なんでもアプリがあるか?というとそんなこともないので、そんなときは自分で作るしかありません。
スクレイピングは常識を超えた範囲で使用すると事件になる可能性があるので気を付けましょう。図書館のスクレイピング事件が有名です。
robots.txtでスクレイピングのルールを確認
web上の情報を自動で収集するプログラムをIT用語でロボット、ボット、クローラーなどと呼びます。新しいwebサイトがgoogle検索上に出てくるのはgoogleのボットが自動でサイト情報を集めているからです。
このロボットがなんでもかんでも情報を集められると困る場合があります。一秒間に1万回も自動でアクセスきたらwebサーバーが落ちてしまいます。そういう時はロボットの活動ルールを定めたrobots.txtをwebサイトに設置します。robots.txtはwebサイトのルートディレクトリに設置します。「www.example.com」なら「www.example.com/robots.txt」です。
ロボットを使って自動で情報を取ってするときはこのrobots.txtを確認して許可されているかどうか確認してから実施しなければなりません。robots.txtが設置されていない場合はロボットの接続は禁止されていないということになります。
テキストにdisallowと書かれている行のディレクトリにはアクセスしてはいけません。スクレイピングの間隔も書かれています。間隔が指定されていない場合でも1秒間は間隔をあけるようにしたほうが良いといわれています。
具体的な設定項目は
- User-agent:ロボットの名称 →google botなど指定したbotに対してルール適用、全ての場合は*
- disallow:パス →許可しないディレクトリパスを記述する。ここのディレクトリにはボットはアクセスしてはいけない
- allow:パス →明示的に許可するディレクトリを指定したい場合
- Crawl-delay: 秒数 →一回クロールしてから空ける間隔
- Request-rate: 秒数当たりの一回のクロール頻度
robots.txtの書式詳細についてはこちら
スプレッドシートのimportxml関数でスクレイピングをしよう
通常スクレイピングをするにはpython等のプログラミング言語や専用のアプリが必要ですが、最も簡単にできる方法のひとつがスプレッドシートの関数を利用する方法です。
googleスプレッドシートのimportxmlという関数を使うと簡単にスクレイピングできます。
さらにgoogle apps scriptを使えば様々なアプリケーションと連携することができます。
importxml関数の使い方
importxml関数は 「=importxml(“URL”, “xpath“) 」と指定するとxpathで指定した情報を取得できます。
参考 IMPORTXML - ドキュメント エディタ ヘルプ取得できませんでした
xpathはxml形式の文章の特定の部分を指定する言語です。細かいことは別の機会に説明しますが、xpathで指定するとwebページの一部分の文章を取得できます。
参考 IMPORTXML - ドキュメント エディタ ヘルプ取得できませんでした
ウェブページのタイトルを取得する
実際にスプレッドシートを使ってウェブページのタイトルを取得してみましょう。
まずは手始めにネットde科学のホームページのタイトルを取得してみます。タイトルはhtmlの<head>タグ内の<title>タグの部分に記載してあることが多いです。xpathを理解していればhtmlのソースコードを見れば指定できると思いますがもっと簡単な方法があります。google chromeやfirefoxなどF12キーを押すと利用できる開発者ツールを使います。chromeの場合の方法を説明します。
- スクレイピングしたいサイトにアクセスする
- F12キーを押す(ブラウザによって開発者ツールとかの名前)
- 取得したいタグ上をクリックして右クリック、Copy Xpathを選択する
- ウェブサイトから選択したい場合は開発者ツールの左端の上にあるセレクトツールを使うとタグが表示される。
- googleスプレッドシート上でimportxmlに記述する
- 取得!

xpathでセレクトする
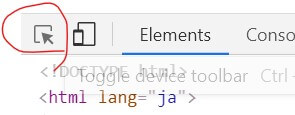
セレクトツール
![]() importxmlでスクレイピング E19にURLを記入して、それをURLとして指定しています。xpathは/html/head/titleを指定、タイトルが取得できてます。
importxmlでスクレイピング E19にURLを記入して、それをURLとして指定しています。xpathは/html/head/titleを指定、タイトルが取得できてます。
xpathを指定する時の注意
xpathは文法をよく知らなくても開発者ツールで簡単に指定できます。しかし、開発者ツールで取得したxpathではimportxmlでうまく取得できないことがあります。その場合はxpathを修正する必要があります。
importxmlでよく起こるxpathのエラーを紹介します。
- ダブルクォーテーションをシングルクオーテーションにする→ xpath中に含まれている” “は’ ‘ に変更しないとエラーになる
- tbodyなど勝手にタグを補足する→保管したtbodyを削除する
- div[1]など番号が実際と異なる。→div[2]など番号変える
などです。
おすすめなのはxpathを取得するプラグインを利用する方法です。xpathの修正にはxpathの知識が必要なのでなかなか難しいと思います。chromeのプラグインに「xpath generator」というものがありこれを利用すると簡単にxpathを取得できます。
参考 XPath Generator - Chrome ウェブストア取得できませんでした
- xpath generatorをchromeに追加
- 取得したいサイトにアクセス
- xpath generatorを起動 (enable generator UI on this pageをクリック)
- ALT+Aを押す
- 取得したいテキストを選択
- 右側にxpathが表示されるのでコピーする

xpath generatorの使い方
xpathを取得する方法はたくさんありますがxpath generatorは修正しなくてもそのまま使えることが多いのでおすすめです。
とはいってもシンプルなwebサイトならよいですが、最近のwebサイトは取得したxpathをそのまま打っても情報が取得できないことが多いと思います。その場合はF12でソースコードを見ながらhtml/bodyなど上のほうの階層からスクレイピングしていってたどっていくと取得しやすいです。
また//div/@id→//div[1]/@idなどのように対象を絞っていくのもやりやすいです。ピンポイントに欲しいデータを手に入れることは難しくてもそのページ中に含まれるリンクのタイトルを取得などは簡単にできます。試しに//a/@hrefなどとxpathを指定してみてください。//a[3]/@hrefのように指定していくと絞っていけます。
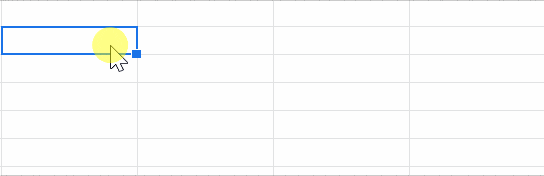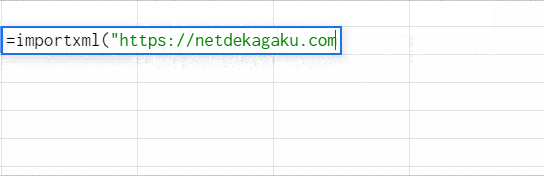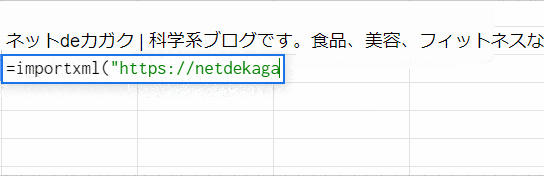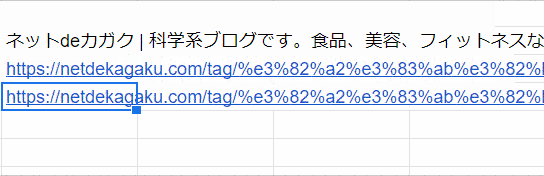
importxmlをスプレッドシートで試した様子
